Diagnosing Rare Diseases for 15¢ per Consult with Claude
It took me about two years and half a dozen doctors to figure out that I have Mast Cell Activation Syndrome (MCAS). About 6% of the population is affected by a rare disease like MCAS, and rare disease patients typically endure more difficult journeys than I did.
Might there be a better way?
I wanted to see how good Claude is at diagnosing rare diseases and see if I can make it better using only public data. To do this, I tested Claude on rare-disease cases — building on the RareArena benchmark, but with 371 fresh cases published after Claude’s training data was frozen, so the model couldn’t have memorized them. Here’s what I found:
I tried different ways of setting up Claude, and each tweak gave a statistically significant improvement. However, I found it challenging to guarantee that the model wasn’t cheating on any of the cases.
Why Rare Disease Journeys Are Hard
A “rare” disease affects fewer than 1 in 2,000 people. There are 7,000+ of them. Together, they touch about 6% of the population — most people know someone affected by a rare disease.
Patients wait almost 5 years on average (4.7) from symptom onset to diagnosis (EURORDIS Rare Barometer). They see on average 7-8 doctors. They’re misdiagnosed 2-3 times (Shire Rare Disease Impact Report, 2013). Primary care doctors and specialists rule out the diseases they know about, but don’t consider the diseases they don’t know about. And often patients hop from doctor to doctor until they find an answer (or give up).
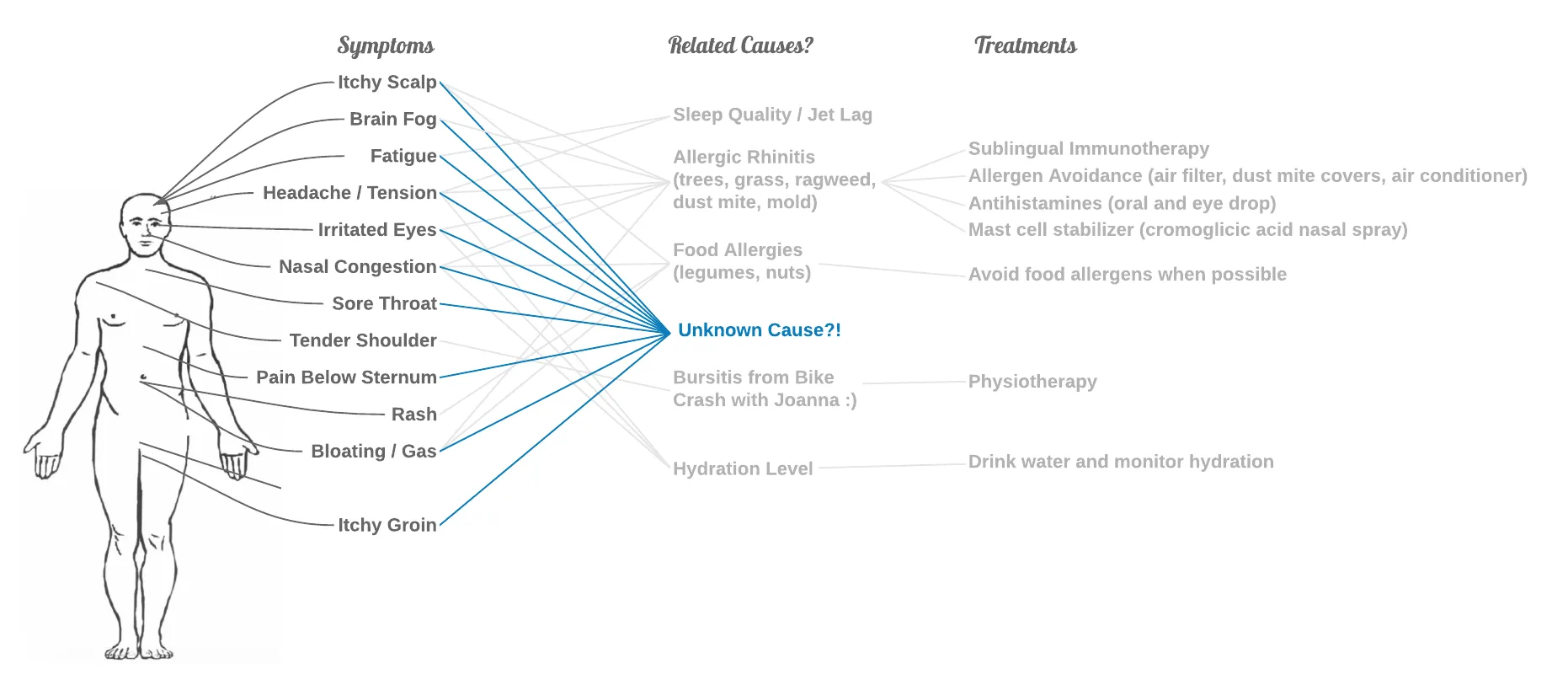
In Berlin, I started having symptoms in May 2019. While I was still in Germany, I saw a family doctor, a histamine intolerance expert, a gastroenterologist, and a nutritionist. Back in San Francisco, starting in 2020, I saw another family doctor and two different complex disease specialists.
Only the last specialist looked broadly enough to find an answer (after asking me to draw 40 tubes of blood in one session!)
Benchmarking And Improving Claude
I built on RareArena (Zhao et al., Lancet Digital Health 2026): 8,562 rare-disease screening cases derived from PubMed case reports, with verified diagnoses from the Orphanet rare-disease database.
Each test gives the model a clinical case write-up — symptoms, history, and physical findings, with the diagnosis stripped out — and asks for a ranked list of the top 5 candidate rare diseases. Here’s what one looks like:
An 11-year-old girl presented with retinal findings on widefield optical coherence tomography imaging. Examination revealed increased thickening of the midperipheral retina bilaterally. In areas of retinal thickening, the retinal architecture showed coarse delineation with thinned and disrupted photoreceptor outer segments. The retinal pigment epithelium appeared normal on autofluorescence imaging. Retrospective review of conventional OCT imaging from age 3 demonstrated that the retinal thickening was already present at that earlier timepoint.
— One of the 371 cases (diagnosis hidden; the model has to produce a top‑5 guess)
Trying for a Valid Benchmark
Two challenges make it hard to run a benchmark using public case data: models might find the exact same case while exploring, or they might memorize case details from their training data.
On the first: Claude with a PubMed or web search tool can find the exact same case at runtime. When I gave it free rein, on about half the cases it looked up the actual case while diagnosing it — a.k.a. cheating. To try to avoid this, I implemented custom PubMed and web search tools that filtered out the case Claude was meant to diagnose, and I had tool-use audits in place to check whether filtering worked correctly. The DeepRare paper took a different and stronger approach: they evaluated their system on newly-collected hospital cohorts that were never published online (so there’s nothing for the model to find), plus ablations with web search disabled.
On the second: the model may have memorized some aspect of the PubMed case during its training. To avoid this, I collected 371 rare-disease cases published after Claude Opus 4.6’s August 2025 training cutoff, with diagnosis-framing language stripped out by a separate, smaller Anthropic model (Haiku) so Claude couldn’t reverse-engineer the answer. I can’t fully guarantee these PubMed cases didn’t leave some online trace that was included in the training data, or that the Haiku cleaning pipeline was perfect — but it’s the best I could do with public data.
Results
To assess how good each setup is, I looked at Top-1 = the model’s first guess is the correct diagnosis, and Top-5 = the correct diagnosis appears anywhere in the model’s top 5 guesses.
I tested three different ways of setting up Claude:
- Vanilla Claude (no tools) — like opening Claude Desktop and asking a question. Got 47.7% right on the first guess, already better than a typical first-visit family doctor.
- Extended thinking — same as vanilla, with extended thinking turned on. Lifted accuracy to 54.9%.
- Tool use — plug in two free public medical databases (PubMed for the literature, the Human Phenotype Ontology for clinical signs and symptoms). Pushed accuracy to 76.0% at roughly $0.15 per consult.
Uncertainty is about ±5pp at this sample size, and each step-up is statistically significant under paired same-case tests (p ≤ 0.001). One important caveat on the tools number: on a 25-case rerun under identical conditions, Claude agreed with itself on only 72% of cases — about a quarter of verdicts flip on a fresh run, since each tool-using run takes a slightly different path. The honest read is that tools-with-public-medical-data lands in the mid-to-high 70s on this set of cases, not exactly 76%.
A few reference points for scale:
- General physician first-visit: ~26% Top-1 — as reported in the RareArena paper.
- DeepRare (Zhao et al., Nature 2026): 57.18% Top-1 averaged across HPO-only public benchmarks, 64.4% on a 163-case real-world hospital cohort (physicians at 54.6%). Different cohorts than I tested on, so this is a ballpark reference, not a head-to-head comparison.
Opportunities & Risks
These are encouraging results, but this is an artificial test. Finding candidate diagnoses is only one step in the medical journey — confirming a diagnosis and starting treatment takes much longer.
Over time, though, it seems likely that Claude might be helpful in the following ways:
- Patient advocacy. A patient can go to their primary care doctor (PCP) with well-sourced candidate diagnoses and have a better chance of going to the right specialist on the first try. Or they may be able to plan confirmatory tests with their PCP first, if the tests are affordable or specialists are not easy to access (e.g., in developing countries).
- Doctor assistance. Doctors might be able to support their patients with faster or higher-quality diagnoses. Or the electronic health records system could spot patterns over time and alert the right doctor.
Medicine is complex, with unintended side effects, so there are many ways that the methods above may fail or not help:
- Real medicine is messy. Claude still gets many cases wrong (24% wrong on Top-1, 16% wrong on Top-5), and it will do even worse with real medical records. Medical history is often not as clean or complete as our test cases. Or it might be affected by patient or doctor biases.
- Common diseases are more common. Techniques optimized for surfacing rare diseases might shift focus too much away from common diseases. Common diseases are often easier to diagnose and cheaper to treat. Chasing a rare disease often means expensive testing and months of stress.
- Privacy. Inputs go to Anthropic, and Anthropic is subject to government pressure and data residency rules.
So this tool may be useful, but mainly as a way to help speed up discussions with a doctor.
Conclusion
From this experiment, I learned that anyone can reach around 70% accuracy in diagnosing rare diseases from PubMed cases — in the same order of magnitude as DeepRare’s reported numbers (though on different cohorts, so not a head-to-head comparison), using only Claude and public medical search tools, a much simpler setup than their multi-agent system with more than 40 specialized tools. It was also humbling to learn how hard it is to know whether the benchmarks are real. It took a couple of rounds of running the benchmark and auditing to lock down different ways Claude might have memorized or cheated.
Try a Diagnosis Yourself With Claude Code
If this might be useful to you, please give this a try and let me know how it works out!
Prerequisites
- uv for the HPO MCP server’s Python dependencies
node&npxfor the PubMed MCP server- Claude Code installed and authenticated
Steps
- Open Claude Code in a folder for this session. If you have medical records you want Claude to read — PDFs of lab results, appointment notes, imaging reports — put them in a folder and start Claude Code there. If you don’t have any yet, an empty folder works too; you’ll describe symptoms in your own words during the consultation.
mkdir -p ~/records # or skip if you already have one
cd ~/records
claude- Install the plugin. In the Claude Code session, paste this and press enter:
“Please install the rare-disease-consult plugin from https://github.com/fryanpan/rare-disease-consult-plugin. Follow the instructions in its AGENT_INSTALL.md file.”
Claude will show a disclaimer, check that you have uv and node/npx (and offer to install them if missing), clone the plugin, register it, and tell you when to restart.
- Start the consultation:
/consultDuring intake, describe symptoms in your own words. If you put records in the folder, you can also point Claude at them: “Please read the files in this folder and use them in the intake.”
If you’d rather install the plugin manually, see the plugin README’s Installation section for the clone + register flow.
A few notes: the first invocation downloads HPO data (~50 MB, ~30 seconds, one-time). Currently Claude Code only — the plugin uses local helper tools (uv and node/npx) that aren’t yet available in Claude Cowork’s hosted runtime. Let me know if you want this to work in Cowork and I can take a look.
Links
- Benchmark + methodology: github.com/fryanpan/rare_disease_benchmark (CC BY-NC-SA 4.0) — full audit and reproduction notes.
- Read the caveats first: the plugin README covers the full risk list. This is v0.1 — it has not been validated on real patient cases.